I saw a search result that said, “A description for this result is not available because of this site’s robots.txt – learn more.” But when I checked that site’s robots.txt, the page was not blocked at all. Did Google just mess this one up?
Magic SEO Ball says: most likely.

I searched for Ray Kurzweil so I could explain to some coworkers that he seriously intends not to die. The fifth and sixth organic results were both from ted.com. The fifth result, but not the sixth, strongly implied that Googlebot had been blocked from crawling the page, and consequently was unable to provide a meta description.
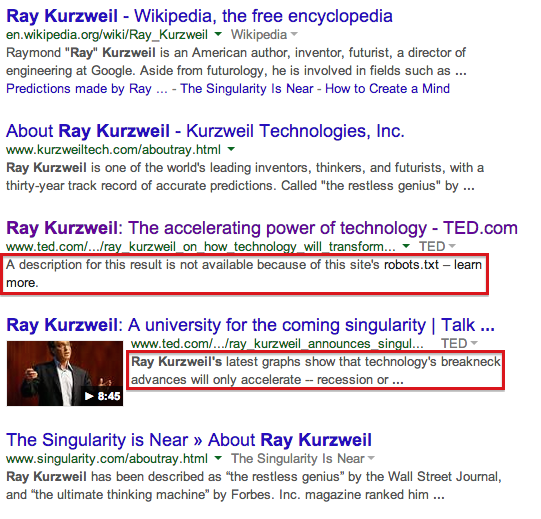
But when I looked at ted.com’s robots.txt, I saw only this:
User-agent: *
Disallow: /index.php/profiles/browse
Disallow: /index.php/search
Disallow: /search
Google wasn’t blocked from crawling the page at all.
I don’t know what’s going on here – specifically whether TED has used another method to prevent this page from being crawled or whether Google actually thinks that the ted.com robots.txt is blocking that directory – but it seems strangely like a Google mistake.